一份寫給普通人的 DeepSeek 速成指南!快收藏
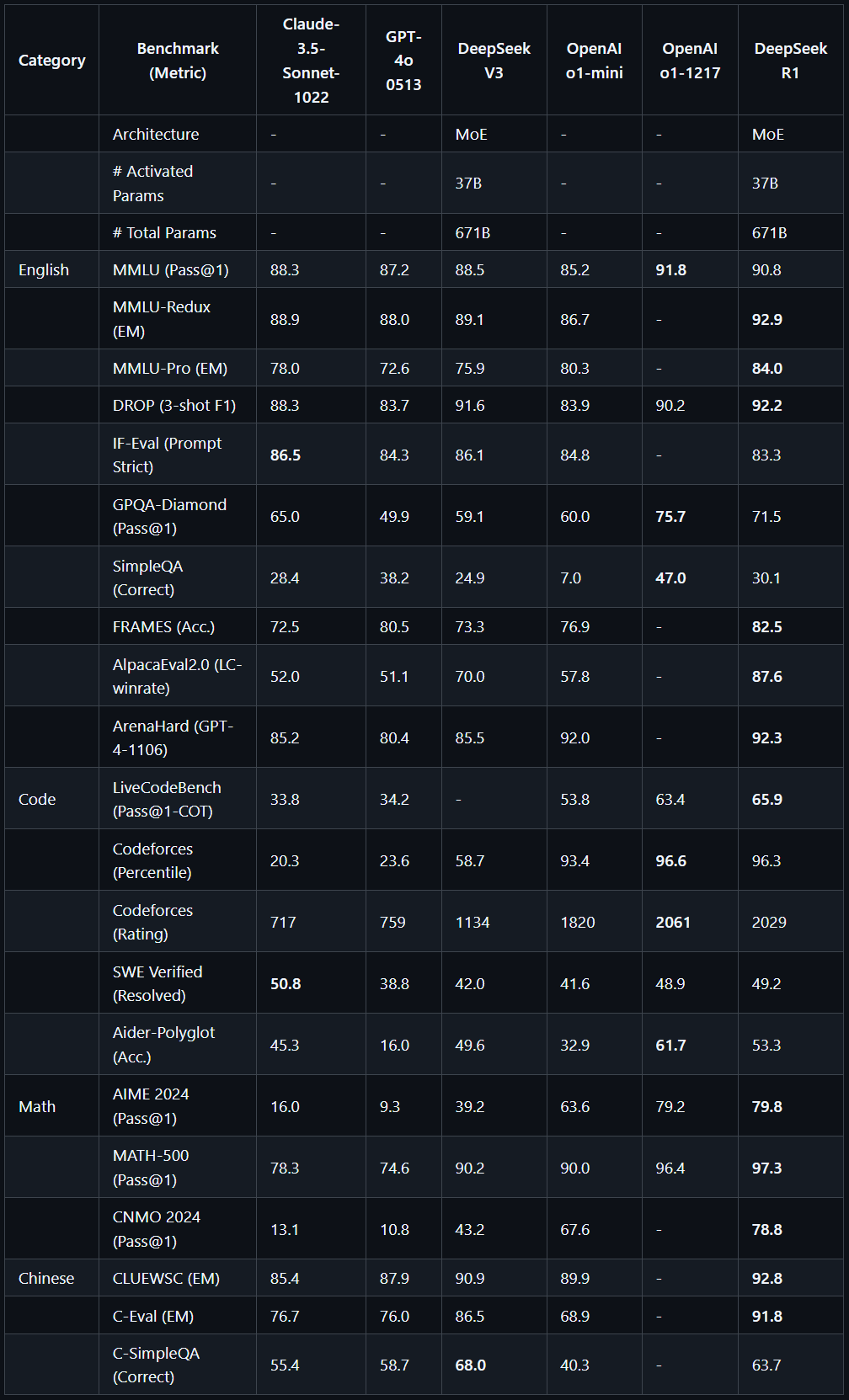
今年春節期間,一顆來自杭州的“AI 新星”悄然崛起,它的名字叫 DeepSeek。它就像一道突如其來的閃電,不僅點亮了全球 AI 的夜空,更為開源社區帶來了一股神秘的“東方力量”。 隨著 DeepSeek 火出圈,越來越多的人開始使用這個 AI 神器。那怎么才能用好它,發揮出它強大的實力呢? 這得從認識它、了解它開始——它就像我們身邊博學但有時會不自覺“腦補”的朋友。它可能會自信滿滿地編造不存在的數據,還會把不相關的信息聯系在一起,又或者生成看似合理但實際錯誤的內容。所以在使用的時候,我們時刻保持警惕,避免錯信 AI 的“胡說八道”。 另外,我們也要不斷學習“如何與 AI 交流”。畢竟即使強大如 Deepseek 這樣的 AI,如果我們說不清楚自己想要什么,它也只能給出模糊不清的答案。 今天,我們整理了一份寫給普通人的 DeepSeek 速成指南,希望能幫助大家用好這個強大的 AI 神器。  本圖由 DeepSeek 指導生成 DeepSeek 到底是如何“思考”的? 如果用一個比喻來描述 DeepSeek,它大概就像是你的一位非常博學多才的朋友,不僅讀過浩如煙海的書籍,更神奇的是,他能瞬間在腦海中建立起各種知識之間的聯系,然后對你知無不答,答無不盡(當然,違法的事情除外)。這就是現代大語言模型的工作方式,而支撐這種能力的核心,是 2017 年 Google 團隊開創的 Transformer 架構。 Transformer 最厲害的本事,就是它的“注意力機制”。打個比方,當你在看一本書時,普通人需要從頭讀到尾,而 Transformer 就像是一個“超級讀者”,能夠一眼就找到文本中最關鍵的信息,并迅速理解它們之間的關聯。 DeepSeek 在成長過程中仿佛一個求知若渴的學霸,它“閱讀”人類積累的海量知識——從枯燥的維基百科到優美的文學作品,從前沿的學術論文到專業的技術文檔,通過不斷預測句子中缺失的詞,逐漸掌握了語言的規律。這個過程與嬰兒通過聽說來學習母語的過程類似,大模型就是在這樣的過程中,慢慢地學會了聽到提問去預測并生成我們想要的內容。 不過,DeepSeek 的“思考”方式也有其獨特之處,它就像是一位即興演講大師,每說出一個詞都經過精密計算,既要保證內容連貫,又要富有創意。但正因為這種即興性,它的回答也會像人類一樣,每次都略有不同。有時候可能妙語連珠,有時候也可能詞不達意,甚至經常會犯錯誤,這就是“ AI 幻覺 ”。 其實在 DeepSeek 之前,國外的 ChatGPT、Claude 早已璀璨奪目,而國內的文心一言、通義千問、Kimi 也各放異彩。為什么偏偏是 DeepSeek 在這個春節后來居上驚艷了全球呢? 答案可以用三個關鍵詞概括:硬實力、性價比、開源共享。 實力過硬:AI界的“技術流”高手 DeepSeek 最與眾不同的是它的“推理腦”。與傳統的指令模型相比,DeepSeek 在模型設計上特別強化了推理能力,借助于通過強化學習等先進技術,它更像是一位善于思考的學者,不僅會聽懂你說什么,更懂得如何深入思考和創新。 目前,DeepSeek R1 已經成為開源大模型中的“最強王者”,它的實力直追 OpenAI 的王牌選手,也成為了開源陣營中唯一能與閉源豪門“掰手腕”的實力派。 上下滑動,查看更多,DeepSeek R1 對比其他主流模型,圖源:作者提供 價格實惠:AI 界的“性價比之王” DeepSeek 不僅技術出眾,而且在成本控制上更是令人嘆為觀止。通過優化訓練方式,他們將 V3 模型的訓練成本壓縮到了 557.6 萬美元——這個數字甚至比不少大模型公司高管的年薪還要低。 這種高效率直接帶來了超低價格,現在百萬 tokens 的輸入只需 4 元,輸出僅需 16 元,有人戲稱它是“大模型界的拼多多”! 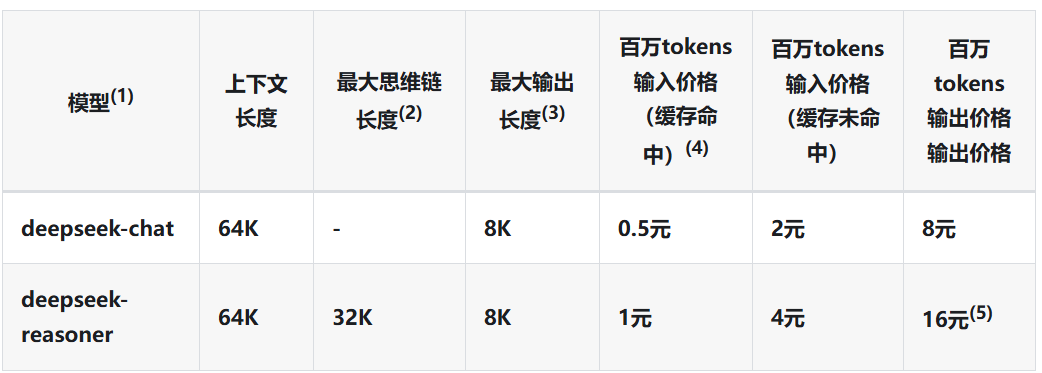 圖源:作者提供 開源共享:AI 界的“武林盟主” 在其他大模型出于商業利益考慮,紛紛設置重重壁壘的時候,DeepSeek 選擇了完全開放代碼,并允許免費商用。這就像一位武林大俠不藏私地公開了畢生絕學,讓整個江湖都能借此提升武藝。 這種開放共享的理念引發了全球共鳴。正如網上流傳的一句妙語,大概意思是:“2025 年的魔幻現實:我們在公益組織(OpenAI)那里買到了月付 200 美元的模型,卻在量化機構那里得到了免費開源的 AI 。” 如何真正用好 DeepSeek? 和 AI 打交道的核心關鍵在于“溝通”。AI 就像是一個被蒙住眼睛的天才,它懂很多,但無法直接感知這個世界。只有通過我們的描述,它才能理解現實世界的樣子。 這就好比你在給一個從未見過大海的人描述海浪的聲音。如果你說“嘩啦嘩啦”,對方可能理解成下雨的聲音;如果你說“像是無數巨大的絲綢在空中抖動”,畫面感就完全不一樣了。同樣的,和 AI 交流就需要這樣的“描述力”。 與 AI 溝通,提示詞就是你的“表達能力”。就像學習一門新語言,這種能力需要不斷練習才能提升。即使是像 Deepseek 這樣強大的 AI,如果我們說不清楚自己想要什么,它也只能給出模糊不清的答案。 還有一點特別重要,AI 的“幻覺”問題。它就像是一個博學但有時會不自覺“腦補”的朋友。它可能會自信滿滿地編造不存在的數據,還會把不相關的信息聯系在一起,又或者生成看似合理但實際錯誤的內容,所以我們要做 AI 幻覺的“執劍人”,時刻保持警惕。 換句話說,AI 是一個強大的工具,但工具的使用效果取決于使用者的能力。通過不斷練習和保持警惕,我們才能真正發揮AI的價值,同時避免掉入“幻覺”的陷阱。 那么,如何用好這個“AI 神器”呢?給大家分享幾個技巧。 1 常規提問模版 過去和 ChatGPT 這樣的指令模型對話時,我們常常會使用很復雜的提示詞模板。但 DeepSeek 不太一樣,它更像一個擅長思考的伙伴,反而是簡單清晰的表達方式效果更好。 非常推薦這個簡單但超級實用的“四步提問法”:背景 + 任務 + 要求 + 補充。舉個例子: 【背景】我是一家新開的咖啡館店主; 【任務】需要一份開業促銷方案; 【要求】預算1萬元內,主要面向大學生群體; 【補充】我們店鋪位于大學城,主打精品咖啡。 這個方法的妙處在于: 背景信息讓 AI 理解你的處境; 具體任務明確你的需求; 限制條件指明關鍵要求; 補充說明添加重要細節。 這樣提問不僅能讓 DeepSeek 更好地理解你的需求,還能避免它理解偏差或者回答跑題。這就像和一個聰明的朋友交談,你把情況說清楚了,他自然能給出更有針對性的建議。 記住,和 DeepSeek 對話,不需要太多花哨的技巧,保持簡單清晰才是王道。它的推理能力很強,只要你把需求說明白,它就能理解你的意圖,并給出令人驚喜的回答。 2 分解復雜任務 現階段 AI 由于上下文,模型能力等問題,其實在處理復雜任務的時候時常會出現“偷懶”這種情況,這種時候就需要我們幫 AI 拆解任務。 接下來用寫一篇“遠程辦公的未來發展”的文章為例,告訴大家怎么一步步指導 AI 完成高質量寫作。 3 連續提問技巧 不要指望 AI 能一次性完成你想要的內容,在使用 AI 時要調整好心態,把它當作一個博學但經驗尚淺的實習生。它知識面很廣,但需要你的引導才能交出令人滿意的作業。 比如上面寫的咖啡店的開業方案,剛產出的第一版肯定是不符合我們的需求,需要通過繼續提問的方式讓它優化內容,直到符合我們的要求。 以上面咖啡店開業方案為例,DeepSeek 寫的第一版方案沒有很好地突出“大學生”這個目標客群。這時候,別急著否定,而是可以這樣繼續對話: 方案的整體框架不錯,但我覺得還可以更貼近大學生群體。能否從以下幾個方面優化: - 如何根據大學生的學習、社交需求設計店內空間? - 考慮到學生的消費能力,怎么設計更有吸引力的價格策略? - 能否結合期末季、社團活動等校園節點設計營銷活動? 就像是在指導實習生,告訴他具體需要改進的方向。DeepSeek 會基于這些新的信息,對方案進行調整。 如果修改后的方案還不夠完善,可以繼續提問: 方案更有針對性了,不過我覺得在這些方面還可以再細化: - 能否加入一些適合學生群體的會員積分制度? - 如何利用社交媒體吸引年輕客群? - 考慮到學生群體的作息特點,營業時間是否需要調整? 這個過程就像是在進行一場頭腦風暴,每一輪對話都在幫助方案變得更加完善。關鍵是要: 1. 保持耐心,不期待一步到位 2. 給出明確的優化方向 3. 循序漸進,一個方面一個方面地改進 4. 及時總結和歸納,確保方向正確 4 巧用不同 AI 每個 AI 就像是一個性格迥異的助手,了解他們的特長,才能讓他們在最合適的崗位上發光發熱。 比如說,DeepSeek R1 就像是一個思維縝密的戰略顧問。給它一個任務,它會從各個角度深入思考,不僅完成你要求的內容,還會主動發現和補充你可能忽略的細節。特別是在做方案規劃時,它總能給出令人驚喜的完整思路。 但是,當涉及到文學創作時,DeepSeek 就像是一個過分熱情的作家,特別喜歡堆砌華麗的修飾語,有時反而影響了文章的整體效果。這時候,性格相對克制的 Claude 就能派上用場,它的文字更加簡潔優雅,更適合處理需要文學性的任務。 知道誰更適合做什么,才能讓團隊發揮最大效能。同樣,在使用 AI 時也是一樣,根據任務性質選擇最合適的“助手”,往往能事半功倍。
表格:自己設計的 該文章在 2025/2/24 11:59:56 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886